 Salesforce Integration
Salesforce IntegrationSalesforce Change Data Capture vs Heroku Connect: Why CDC Alone Isn't Enough for Real-Time Operational Sync
by Atypical Tech · Published on 15 May 2026
Salesforce Change Data Capture vs Heroku Connect: Why CDC Alone Isn't Enough for Real-Time Operational Sync
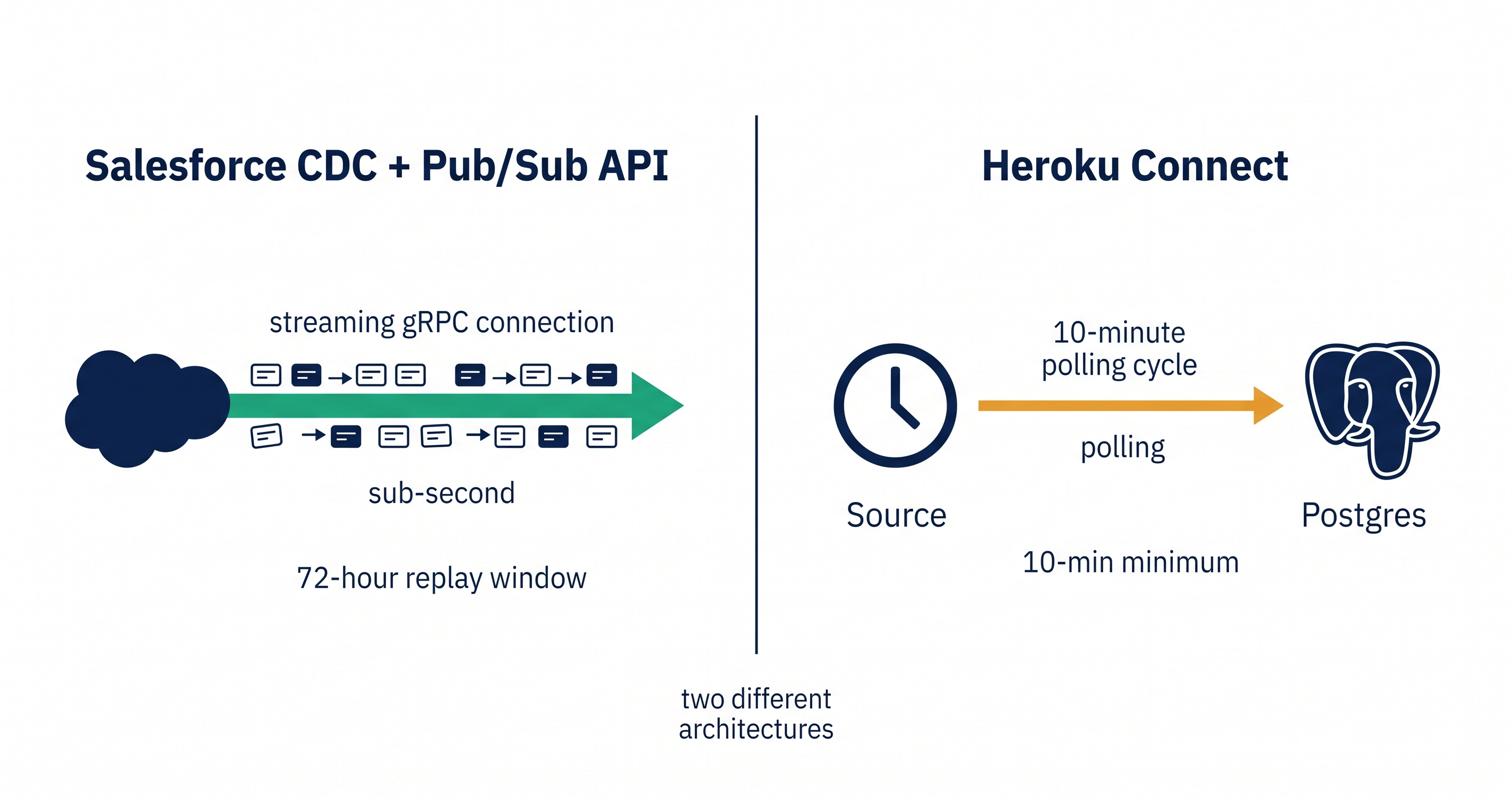
Salesforce CDC is a near-real-time event stream over Pub/Sub API. Heroku Connect is polling-based bidirectional sync with a 10-minute minimum interval. They solve different problems: CDC streams events at sub-second latency, Heroku Connect maintains state and bidirectional writes. Most production teams need both — CDC plus replay, conflict resolution, and write-back. Here is the honest comparison.
This question moved from theoretical to urgent on February 6, 2026, when Salesforce put Heroku into sustaining engineering mode and engineering teams began re-evaluating whether to keep paying for Heroku Connect or build on top of CDC themselves. For migration urgency framing, see our companion post on Heroku Connect end of life. For a close-up on warehouse-destination paths that bypass Heroku entirely, see Salesforce to Snowflake real-time sync without Heroku Connect.
What Salesforce CDC actually is
Salesforce Change Data Capture is the event-streaming primitive in the Salesforce platform. When a record in any subscribed object is created, updated, deleted, or undeleted, Salesforce publishes a change event. Consumers receive those events through the Pub/Sub API, a gRPC streaming endpoint that replaced the older CometD-based streaming. The canonical reference is the Salesforce Developers CDC documentation.
A few specifics matter for the comparison:
- CDC events carry the changed fields and a replay ID. Consumers can resume a stream from a specific replay ID up to a 72-hour retention window.
- Delivery is at-least-once. Consumers must dedupe on the change-event ID.
- CDC events are one-way: Salesforce → consumer. There is no write-back primitive.
- Pub/Sub API is gRPC-based, supports binary Avro payloads, and is more efficient than the older CometD streaming. It is the recommended client.
- Salesforce runs CDC events through internal infrastructure, so latency is typically sub-second end-to-end from a record being saved to a consumer receiving the event.
CDC is one of three event channels in Salesforce. The other two are Platform Events (custom-fired events you publish from Apex or APIs) and Generic Streaming (legacy). For sync use cases, CDC is the right channel — it carries the actual record-change semantics teams need.
What Heroku Connect actually does
Heroku Connect is a managed bidirectional sync between Salesforce and Heroku Postgres. The architecture is fundamentally different from CDC. According to the Heroku Dev Center performance documentation, Heroku Connect runs on a polling model with a 10-minute minimum interval. It queries Salesforce on a schedule, fetches changed records, and writes them into a corresponding Postgres schema.
Three things are notable:
- Heroku Connect maintains state — your Postgres schema is a queryable replica of the Salesforce objects. CDC, by itself, does not produce a replica; it produces a stream.
- Heroku Connect is bidirectional. When a Postgres row changes, Heroku Connect writes the change back to Salesforce on the same polling cycle. CDC has no built-in write path.
- Heroku Connect's polling consumes Salesforce's API quota. Per the Heroku Help center, Heroku Connect contributes to your org's streaming API rate limit — meaning a busy Heroku Connect deployment can throttle other Salesforce integrations.
Heroku Connect is the legacy answer to "I want Salesforce data in a relational database, with writes going both ways, without writing my own pipeline." It works, but it is a polling-era product, and the trade-offs (latency, lock-in to Heroku Postgres, sustaining-mode strategic risk) are now widely understood.
Side-by-side comparison
The table below maps the two onto the seven dimensions that matter for production sync. Note: the rightmost column captures what most teams actually need — and notice how often neither CDC alone nor Heroku Connect alone covers it.
| Capability | Salesforce CDC | Heroku Connect | What production teams actually need |
|---|---|---|---|
| Latency | Sub-second (push) | 10-min minimum (poll) | Sub-second |
| Direction | One-way (SF → consumer) | Bidirectional | Bidirectional |
| Output target | Anything that consumes Pub/Sub gRPC | Heroku Postgres only | Any modern Postgres + warehouses |
| Replay window | 72 hours | N/A (state-based) | Permanent / configurable |
| Schema mapping | None (raw Avro) | Manual via Heroku Connect mapping | Automatic with overrides |
| Conflict resolution | None | Last-write-wins | Configurable per object |
| Salesforce API consumption | Streaming, lower | Polling, high | Streaming preferred |
Read across each row. Where the "actually need" column matches CDC, you can use CDC alone. Where it matches Heroku Connect, you can use Heroku Connect alone. Most rows match neither. That is the architectural reality.
What you can build with Salesforce CDC alone
CDC alone solves a specific class of problems well.
One-way streams to a stream processor. If you already operate Kafka, Kinesis, or AWS EventBridge, CDC fits cleanly. The Pub/Sub API client emits events into your stream processor, downstream consumers do whatever they need. This is the pattern Salesforce officially recommends for event-driven downstream apps.
Materialized views in a warehouse. Many teams stream CDC events into a Snowflake / BigQuery / Databricks landing schema, then dbt-transform from there. Latency is sub-minute end-to-end, costs are low (you pay Snowflake ingestion + Pub/Sub API consumption), and the architecture is straightforward.
Read-only operational caches. If you need a Postgres or Redis cache of Salesforce data for read-heavy applications, CDC + a thin consumer that maintains the cache works. The catch: you have to handle deletes carefully (CDC reports deletes but consumers must process them, not skip them).
Where CDC ends. CDC alone cannot:
- Write back to Salesforce (no write primitive)
- Replay events older than 72 hours
- Do an initial bulk load (CDC is incremental; backfill needs Bulk API 2.0)
- Detect schema drift in your destination
- Resolve conflicts between Salesforce and a writable destination
What you can't build with CDC alone — and what Heroku Connect was solving
The original Heroku Connect value proposition was: don't build a sync pipeline; we'll maintain a Postgres replica with writes going both ways. To replicate that outcome with CDC, you need to build five additional layers.
Bidirectional write-back. Salesforce REST API or Bulk API 2.0 handle writes back to Salesforce. You need idempotency keys to prevent double-writes during retries, dedupe logic to avoid loops between CDC events and your own writes, and rate-limit handling because the Salesforce REST API has org-level limits.
Initial bulk load. CDC is incremental. To populate a destination from scratch, you fetch the existing data via Bulk API 2.0, then start consuming CDC from a replay ID that overlaps the bulk-load timestamp. Done wrong, you get duplicate rows or missing rows. Most teams underestimate how much engineering this needs.
Hard deletes. CDC reports deletes, but Salesforce hard-deletes after the recycle bin window. If your CDC consumer is offline during the hard-delete event, you lose the chance to apply it. Heroku Connect surfaces this as part of its normal polling cycle.
Replay beyond 72 hours. If your consumer goes offline for 73 hours (a long incident, a code-deploy gone wrong, a multi-day debug), CDC can't help you catch up. You need either a Kafka topic in front of your consumer with longer retention, or a periodic full-reconciliation job that compares your destination against a Bulk API snapshot.
Schema-drift detection. Salesforce admins add fields. Custom fields appear. CDC events carry the new field; your destination doesn't have a column for it; the change silently disappears. You need a layer that detects schema changes in CDC events and either evolves the destination schema or alerts.
These five layers are what turn a CDC stream into a production-grade sync system. Either you build them, or you adopt a managed platform that bundles them. We cover the build-vs-buy tradeoff in detail in our companion post on build vs buy: replacing Heroku Connect with Debezium, Airbyte, or a managed sync platform.
The architecture teams are converging on (post-Heroku-Connect)
A modern Salesforce sync stack in 2026 typically has these layers, regardless of whether you build or buy:
Salesforce
│ (CDC events via Pub/Sub API; Bulk API 2.0 for initial load)
▼
Stream consumer (Kafka topic, managed CDC platform, or custom gRPC client)
│
├──► Postgres replica (operational reads)
├──► Snowflake / BigQuery (analytics)
└──► Reverse path: write-back via REST or Bulk API 2.0
with idempotency + dedupe + conflict resolution
Whether the boxes in this diagram are a managed platform (Stacksync, Whalesync, Bracket) or a self-hosted stack (Debezium-style consumer + Kafka + custom write-back) is the build-vs-buy question. The shape of the architecture is the same.
This is the pattern Heroku Connect could not evolve into. Heroku Connect's polling model is fundamentally one-tier. There is no event stream, no replay-able log, no write-back path that is independent of the polling cycle. To get to the modern shape, you have to leave Heroku Connect — there is no in-place upgrade. For more on Heroku Connect's specific architectural limits, see Stacksync's deep dive on Heroku Connect's architecture limits.
When CDC alone is enough
Some teams genuinely don't need the full sync stack. CDC alone fits when:
- The destination is read-only. Analytics warehouses, search indexes, caches.
- 72-hour replay is sufficient. Your consumer has high uptime and short downtime windows.
- You don't need an initial bulk load. The system is new; it can start at the current state.
- The data volume is moderate. Pub/Sub API throughput is enough; you don't need Kafka in front.
- You already operate a stream platform in production (Kafka, Kinesis, EventBridge).
If you check all five boxes, run CDC directly into your stream platform and skip the managed-sync question entirely.
When you need more than CDC
Most production teams need more. The two strong indicators:
You have an operational use case. Customer-facing apps reading Salesforce-derived data, support tools that write back to Salesforce, RevOps automation that updates Salesforce records based on warehouse models. Operational means writes both directions, conflict resolution matters, and downtime hurts.
You have a multi-org or multi-tenant Salesforce deployment. Each org has its own CDC stream, its own API limits, its own schema. Aggregating across orgs requires per-tenant routing, conflict-resolution that's tenant-aware, and observability that lets you see per-tenant health. Building this from CDC primitives is multi-quarter engineering. Managed platforms typically include it.
If either applies, do not build a sync system from CDC alone. Either adopt a managed platform or commit to a 3-to-6-month build. There is no middle path that works in production.
FAQ
Is Salesforce CDC a Heroku Connect replacement?
No, not by itself. Salesforce CDC provides the change-event source, but it does not include bidirectional sync, schema mapping, conflict resolution, replay beyond 72 hours, or initial bulk loading. To replicate Heroku Connect's outcome you need CDC plus a consumer, plus Bulk API 2.0 for initial load, plus a write-back path, plus schema-drift detection. Either you build that stack or you use a managed platform that bundles it.
Can I use Salesforce CDC for bidirectional sync?
No. CDC is a one-way event stream from Salesforce to consumers. To write back to Salesforce, you use the REST API or Bulk API 2.0 and handle idempotency, dedupe, and conflict resolution yourself. Bidirectional sync is the layer that goes on top of CDC, not part of CDC.
What is the latency of Salesforce CDC?
End-to-end latency from a record being saved in Salesforce to a Pub/Sub API consumer receiving the event is typically sub-second. The exact figure depends on Salesforce's internal queue depth, your consumer's location relative to the Salesforce region, and gRPC connection health. Plan for under 1-second latency in normal conditions; expect occasional 2–5 second spikes under load.
How long does Salesforce CDC retain events?
The CDC retention window is 72 hours. Consumers can resume a stream using a stored replay ID up to that horizon. Events older than 72 hours are unavailable; recovering them requires a Bulk API 2.0 snapshot reconciliation. For longer-retention needs, route CDC events into a Kafka topic with a configurable retention period.
Does Salesforce CDC consume API quota?
Yes, but at a much lower rate than polling. Pub/Sub API usage counts against the streaming-API event-publishing limits, not the synchronous REST API call limits. A Heroku Connect deployment polling every 10 minutes typically consumes more API budget than an equivalent CDC consumer running on Pub/Sub API, per the Heroku Help documentation on streaming API rate limits.
What's the difference between Salesforce CDC and Platform Events?
Salesforce CDC publishes record-change events automatically when objects are created, updated, deleted, or undeleted. Platform Events are custom events your code publishes from Apex or APIs. CDC is for sync use cases (record state changes); Platform Events are for application-level events (a custom workflow firing). Both run on the Pub/Sub API.
Can I write to Salesforce from a Postgres database using CDC?
Not directly. CDC is the wrong direction — it is Salesforce → consumer, not consumer → Salesforce. To write from Postgres back to Salesforce, you need a separate path: typically Postgres logical replication or triggers feeding a consumer that calls the Salesforce REST API or Bulk API 2.0. Managed bidirectional sync platforms (including Stacksync) bundle both directions; building from primitives requires both pipelines.
Why doesn't Heroku Connect use Salesforce CDC under the hood?
Heroku Connect predates the Pub/Sub API and CDC's current shape. Salesforce has not modernized Heroku Connect to use CDC, which is one of the main reasons Heroku Connect's latency floor is 10 minutes — the polling architecture is structural, not a tunable. With Heroku in sustaining mode, this modernization is unlikely to happen.
Closing — Next steps for teams replacing Heroku Connect with a CDC-based stack
Three concrete next steps:
- Decide whether you need bidirectional or one-way. If one-way is enough, a CDC consumer landing into your warehouse is the simplest path.
- If you need bidirectional, decide build vs buy. Honest answer: under 100M events per day and fewer than 5 senior backend engineers, buy. Above that or with strategic ownership requirements, build. We dig into this in build vs buy: replacing Heroku Connect with Debezium, Airbyte, or a managed sync platform.
- Get specific about latency and replay needs. "Real-time" means different things at different volumes. If your operational SLA is "Salesforce changes appear in Postgres within 5 seconds," CDC + a managed platform is overkill compared to what most teams actually need; if it's "within 100ms for revenue-critical workflows," your design changes considerably.
Stacksync's product page covers what real-time bidirectional sync that scales looks like end-to-end on the buy path.
About the authors
[AT integration architect — name TBD], Integration Architect, Atypical Tech. [Bio paragraph: 60–80 words on integration architecture, Salesforce platform experience, iPaaS implementations across NetSuite/Dynamics/Salesforce. To be filled with real engineer profile before publish.] LinkedIn.
[Stacksync solutions architect — name TBD], Solutions Architect, Stacksync. [Bio paragraph: 60–80 words on Salesforce Pub/Sub API, CDC, Bulk API 2.0, Postgres logical replication. To be filled with real engineer profile before publish.] LinkedIn.
Sources
- Salesforce Developers — Change Data Capture: https://developer.salesforce.com/docs/atlas.en-us.change_data_capture.meta/change_data_capture/cdc_intro.htm
- Salesforce Developers — Pub/Sub API Overview: https://developer.salesforce.com/docs/platform/pub-sub-api/overview.html
- Salesforce Developers — Platform Events: https://developer.salesforce.com/docs/atlas.en-us.platform_events.meta/platform_events/platform_events_intro.htm
- Salesforce Developers — Bulk API 2.0: https://developer.salesforce.com/docs/atlas.en-us.api_asynch.meta/api_asynch/asynch_api_intro.htm
- Heroku Dev Center — Diagnosing Heroku Connect Performance Issues: https://devcenter.heroku.com/articles/diagnosing-heroku-connect-performance-issues
- Heroku Dev Center — Optimizing Heroku Connect Performance: https://devcenter.heroku.com/articles/optimizing-heroku-connect-performance
- Heroku Help — Streaming API rate limit and Heroku Connect: https://help.heroku.com/F6F6FTGZ/why-is-my-heroku-connect-usage-contributing-to-my-salesforce-org-s-streaming-api-rate-limit